Introduction to Gemini Pro Vision : Aritra Roy Gosthipaty and Ritwik Raha
by: Aritra Roy Gosthipaty and Ritwik Raha
blow post content copied from PyImageSearch
click here to view original post
Table of Contents
Introduction to Gemini Pro Vision
In this tutorial, you will learn how to get started with Gemini Pro Vision.

To learn how to use Gemini Pro Vision for your own use cases, just keep reading.
Introduction to Gemini Pro Vision
In the last few days of 2023, Google came up with the major announcement of the year — Gemini has been released.
For those unaware, Gemini is the most powerful Google Large Language Model (LLM) to date. It also boasts of being multimodal from scratch, which means it began and ended as a model capable of dealing with multiple modalities of data (image, video, sound, etc.).
Gemini Pro is now available in Bard through the MakerSuite UI and their Python Software Development Kit (SDK).
Google AI Studio
Explore the Gemini Pro and Gemini Pro Vision models accessible via the MakerSuite UI within Google AI Studio. This browser-based integrated development environment (IDE) specializes in prototyping with generative models, enabling swift experimentation with diverse prompts. Upon creating content that satisfies you, leverage the Gemini API to export your work into code compatible with your preferred programming language.
Within Google AI Studio, diverse prompt interfaces cater to specific purposes:
- Unrestricted Freeform Prompts: Encouraging open-ended content generation and response creation using both text and image data.
- Structured Prompts: Guiding model output by offering a set of example requests and responses, ideal for exerting precise control over output structures.
- Chat Prompts: Crafting conversational experiences by facilitating multiple input and response turns to generate output.
Creating a Prompt Using Google AI Studio
Let us first view the two images we will be uploading to the Studio. They are two adjacent panels from Batman: The Dark Knight Returns by Frank Miller.
 |
 |
We can name our prompt and provide a description of it. This is for our reference only and won’t be seen by the Model.
Next, we provide a prompt (this is optional but highly recommended) where we specify what we want the model to do for us.
Since our primary objective is to understand the content of the images, we specify our prompt to be:
Describe these two images in detail, explain what is happening also mention the book and the author
With that done, we can set the temperature to our liking and add any stop sequence. We can also experiment with the safety settings and advanced settings to increase the model’s performance.
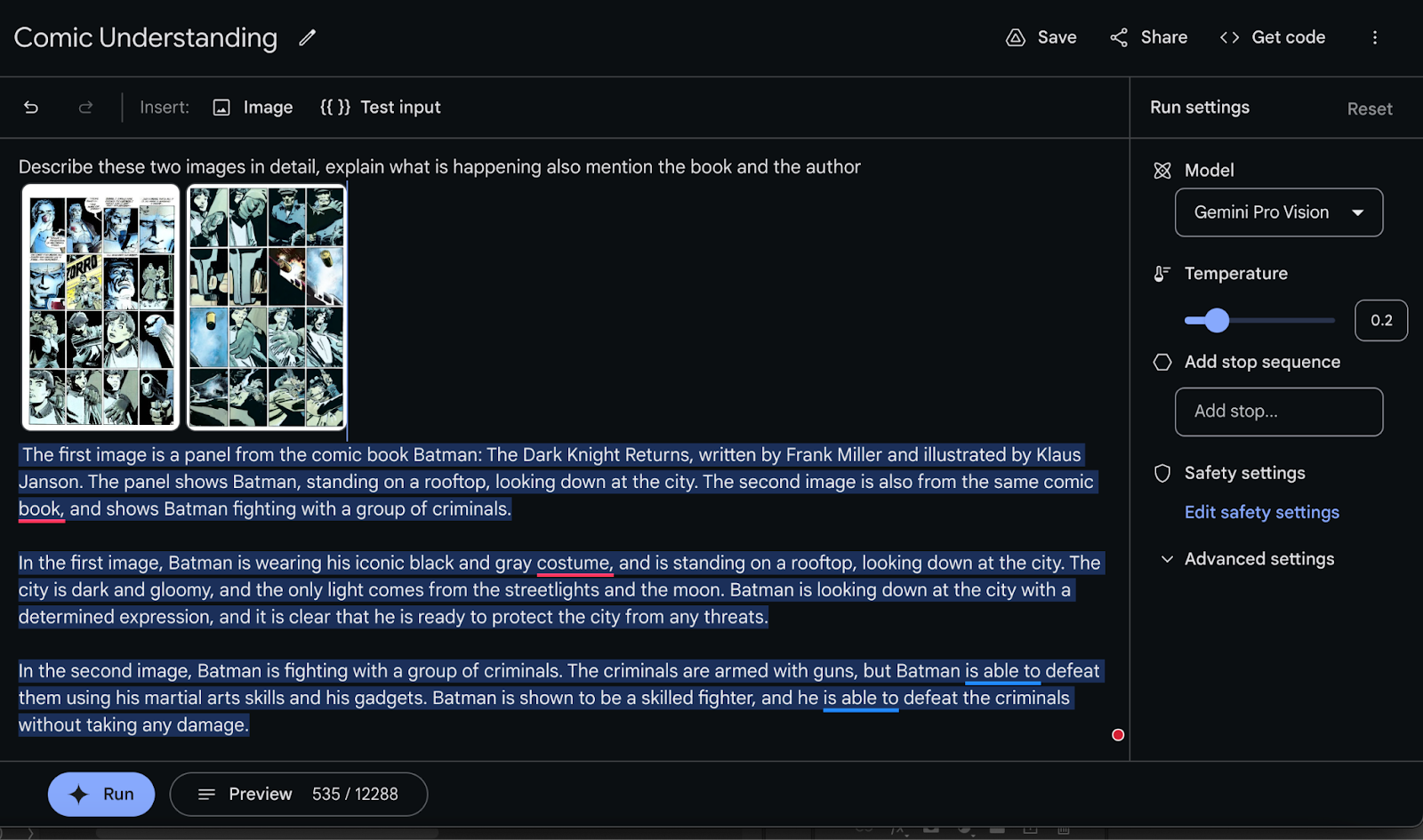
We can see the model has finished running, and the output is shown below:
The first image is a panel from the comic book Batman: The Dark Knight Returns, written by Frank Miller and illustrated by Klaus Janson. The panel shows Batman, standing on a rooftop, looking down at the city. The second image is also from the same comic book, and shows Batman fighting with a group of criminals. In the first image, Batman is wearing his iconic black and gray costume, and is standing on a rooftop, looking down at the city. The city is dark and gloomy, and the only light comes from the streetlights and the moon. Batman is looking down at the city with a determined expression, and it is clear that he is ready to protect the city from any threats. In the second image, Batman is fighting with a group of criminals. The criminals are armed with guns, but Batman is able to defeat them using his martial arts skills and his gadgets. Batman is shown to be a skilled fighter, and he is able to defeat the criminals without taking any damage.
The initial information is accurate. It has correctly identified the book and the author as well as the illustrator. But the remainder of the information is pure hallucination where the model goes off describing generic scenes from the Batman lore.
Gemini Pro Vision API
This section demonstrates how to use the Python SDK for the Gemini API, which provides access to Google’s Gemini LLMs. The following is the actual specification of the Gemini Pro Vision model, as mentioned in the documentation.
|
||
|
||
generateContent |
||
12288 |
||
4096 |
||
!pip install -q -U google-generativeai
Line 1: Installs the google-generativeai library, which provides functionalities to interact with Google’s generative AI models.
import pathlib import textwrap import google.generativeai as genai from IPython.display import display from IPython.display import Markdown import PIL.Image import urllib.request from PIL import Image
Lines 3-13: Import various modules necessary for handling images, displaying outputs in Colab, and managing API keys securely. pathlib and textwrap are for file and text manipulation, google.generativeai (aliased as genai) is the main module for AI functionalities, and PIL.Image and urllib.request are for handling and downloading images.
# Used to securely store your API key
from google.colab import userdata
# Or use `os.getenv('GOOGLE_API_KEY')` to fetch an environment variable.
GOOGLE_API_KEY=userdata.get("GEMINI_API_KEY")
genai.configure(api_key=GOOGLE_API_KEY)
Lines 16-19: Set up secure storage for the API key with userdata.get from Google Colab, which is a secure way to store and retrieve user-specific data like API keys.
for m in genai.list_models():
if "generateContent" in m.supported_generation_methods:
print(m.name)
Lines 23-25: The script lists and prints the names of available models in the google-generativeai library that support content generation. This step helps in understanding what models are available for use. We can see from the output below that gemini-pro and gemini-pro-vision are available for use.
models/gemini-pro models/gemini-pro-vision
# Opening the image for Image Understanding
urllib.request.urlretrieve(
'https://i.imgur.com/RxsIzEy.png',
"comic.png")
image = PIL.Image.open('comic.png')
image
Lines 28-32: Download an image from a specified URL and open it using the PIL (Python Imaging Library). The image is then displayed in the Colab notebook.
model = genai.GenerativeModel("gemini-pro-vision")
def to_markdown(text):
text = text.replace("•", " *")
return Markdown(textwrap.indent(text, "> ", predicate=lambda _: True))
response = model.generate_content(image)
to_markdown(response.text)
Line 34: Initializes a generative model named “gemini-pro-vision” from the google-generativeai library, presumably for image understanding and content generation.
Lines 35-37: Define a helper function to_markdown to format the generated text as Markdown, enhancing the readability of the output in Colab.
Lines 38 and 39: Generate content based on the previously loaded image. The response is converted to Markdown format for display.
"Just a movie. That's all it is. No harm in watching a movie."
response = model.generate_content(
["Write an explanation based on the image, give the name of the author and the book that it is from", image],
stream=True
)
response.resolve()
to_markdown(response.text)
Lines 41-47: Generate content with a specific prompt (“Write an explanation based on the image, give the name of the author and the book that it is from”) and the image. The stream=True parameter indicates that the response is streamed, and response.resolve() waits for the completion of this streaming response. The result is again formatted as Markdown.
The image is from the comic book "Batman: The Dark Knight Returns" by Frank Miller. It shows Batman confronting a young man who has been terrorizing the city. Batman tells the young man that he is not a hero, but a criminal. The young man tries to justify his actions by saying that he is only doing what Batman does, but Batman tells him that he is not the same as him. Batman says that he has a code, and that he only hurts criminals. The young man asks Batman why he doesn't kill him, and Batman tells him that it is because he does not want to become like the criminals he fights.
Again, we see that it produces specific information correctly (e.g., the name of the author and the name of the book) but hallucinates and references a different panel from the same book.
- Is this because it fetches the name of the book first and then tries to fetch the most relevant or accessible information it has compressed about the book?
- Is the model actually able to understand how the objects in the image are related?
- Is it able to identify that multiple objects (characters) are the same entities drawn from different angles?
These are questions that need the underlying layers’ latent embeddings to be answered. Unfortunately, these models are no longer open sourced and probably will never be.
What's next? We recommend PyImageSearch University.
83 total classes • 113+ hours of on-demand code walkthrough videos • Last updated: December 2023
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 83 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 83 Certificates of Completion
- ✓ 113+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 532+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Gemini Pro Vision has been marketed as an all-purpose Vision model that can solve any and every range of tasks presented to it.
Multimodal Use Cases: Compared to text-only LLMs, the Gemini Pro Vision’s multimodality can be used for many new use cases.
Example use cases with text and image(s) as input include the following:
- Detecting objects in photos
- Understanding screens and interfaces
- Understanding of drawing and abstraction
- Understanding charts and diagrams
- Recommendation of images based on user preferences
- Comparing images for similarities, anomalies, or differences
- Example use cases with text and video as input:
- Generating a video description
- Extracting tags of objects throughout a video
- Extracting highlights/messaging of a video
At the moment, however, the Gemini Pro Vision does not excel in some of the above tasks. For example, in this tutorial, we saw how to install the google-generativeai library and then use it for image-understanding tasks. The image was complex and not straightforward, which allowed us to really test the model.
What unique use cases can you come up with? Let us know @pyimagesearch on social media channels.
Citation Information
A. R. Gosthipaty and R. Raha. “Introduction to Gemini Pro Vision,” PyImageSearch, P. Chugh, S. Huot, and K. Kidriavsteva, eds., 2024, https://pyimg.co/e3glw
@incollection{ARG-RR_2024_IntroGeminiProVision,
author = {A. R. Gosthipaty and R. Raha},
title = {Introduction to Gemini Pro Vision},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva},
year = {2024},
url = {https://pyimg.co/e3glw},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.
The post Introduction to Gemini Pro Vision appeared first on PyImageSearch.
January 01, 2024 at 07:30PM
Click here for more details...
=============================
The original post is available in PyImageSearch by Aritra Roy Gosthipaty and Ritwik Raha
this post has been published as it is through automation. Automation script brings all the top bloggers post under a single umbrella.
The purpose of this blog, Follow the top Salesforce bloggers and collect all blogs in a single place through automation.
============================


Post a Comment