Photogrammetry Explained: From Multi-View Stereo to Structure from Motion : Jeremy Cohen
by: Jeremy Cohen
blow post content copied from PyImageSearch
click here to view original post
Table of Contents
Photogrammetry Explained: From Multi-View Stereo to Structure from Motion
In this blog post, you will learn about 3D Reconstruction.

This blog post is the 1st of a 3-part series on 3D Reconstruction:
- Photogrammetry Explained: From Multi-View Stereo to Structure from Motion (this blog post)
- 3D Reconstruction: Have NeRFs Removed the Need for Photogrammetry?
- 3D Gaussian Splatting: The End Game of 3D Reconstruction?
To learn about 3D Reconstruction, just keep reading.
Photogrammetry Explained: From Multi-View Stereo to Structure from Motion
Should you shoot with one eye closed or both eyes open?
During the 2024 Paris Olympics, something unusual caught my eye during the shooting competition. While most athletes wore specialized glasses, eye covers, and high-tech gear to sharpen their precision, one Turkish shooter, Yusuf Dikeç, stood out. He shot with both eyes open, no elaborate equipment, and an air of effortless confidence.
I immediately wondered: “How did he shoot with both eyes open?” I always assumed you had to close one eye to focus with your dominant one. This is also what I learned when shooting for the first time. And after a quick search, I realized that many professional shooters actually train to keep both eyes open. This is not just a stylistic choice but a technique that can improve depth perception, situational awareness, and reaction time.
In the same way, when we think about 3D reconstruction and photogrammetry, we rely on a similar principle.
Whether it’s using multiple cameras or a flying drone to take pictures, we use multiple viewpoints to get a better sense of depth and even reconstruct an entire 3D scene.
Today, you may have come across many ways to do 3D reconstruction: Structure from Motion, Visual SLAM (Simultaneous Localization And Mapping), NeRFs, Stereo Vision, 3D Gaussian Splatting… In reality, there are 3 main families of algorithms, and I want to cover them in a mini-series of 3 blog posts:
- This first blog post will explore Photogrammetry, which we can see as the geometric solution to 3D reconstruction.
- The second blog post will introduce you to NeRFs, the neural network solution.
- Finally, the last blog post will talk about 3D Gaussian Splatting, which combines both solutions and is currently the favored technique.
So, let’s begin with Photogrammetry!
You may have recently heard this term via Apple and Google, or you may have seen them when studying techniques to take an image to a 3D model, when learning SLAM, or when looking at 3D Computer Vision. In reality, there are two main photogrammetry methods involved:
- Multi-View Stereo
- Structure from Motion
So what is it about? Let’s take a look, and then we’ll see some examples…
Technique #1: Multi-View Stereo
The first technique that photogrammetry relies on comes from one of my favorite Computer Vision ideas: 3D Computer Vision. If you’ve never come across it, please read my complete roadmap here. The core idea? Images are not meant to stay 2D, you can create 3D models from 2D images… And the most obvious way to do this is via Stereo Vision.
When you’re using stereo cameras, you can triangulate the 3D positions of each pixel, and therefore recover a 3D point cloud.
The process looks like this:

Have you seen how we’re able to reconstruct the 3D scene using just two cameras? This is an idea many Computer Vision Engineers totally miss — because they’re so focused on image processing, Deep Learning, and OpenCV that they forget to take the time to understand cameras, geometry, calibration, and everything that really draws the line between a beginner Computer Vision Engineer, and an Intermediate one.
So how does that work? The process, explained in depth in my Pseudo-LiDAR post, looks like this:
- Estimate a depth map from a stereo pair
- Use the camera’s parameters to turn the depth map into a 3D point cloud

Awesome! So now, we have a 3D scene, and we can actually interact with it!

So what is “Multi-View” Stereo? Well, do you notice all those white “holes” in our 3D scene? It’s because it’s only a two-view reconstruction — from two cameras.
If we add more cameras, we add more viewpoints, and thus, we can fill the holes and recover a 3D view. This is the idea of multi-view stereo. We can use 3, 4, 5, or even 10 overlapping images and retrieve a complete 360° view of a scene or physical objects:

The process is iteratively doing 2-View reconstructions. First, between cameras 1 and 2. Then, between 2 and 3. Then 3 and 4. And so on… Since we know exactly all the camera parameters, we’re just overlapping 2-View Reconstructions. In some cases, algorithms like the Iterative Closest Point (ICP) can also align the point clouds together for a better output.
Now, there are cases when you cannot do this, for example, when you don’t know the camera’s relationship to each other. We’re having images, but we don’t know how far camera 1 is from camera 2, or how oriented they are, and so on…
The problem is called Structure from Motion (SfM).
Technique #2: Structure from Motion
Now comes Structure from Motion, and as I explained, this happens when you don’t know the camera parameters or relationships to each other, and you can’t easily do the 3D Reconstruction:

If we still want to reconstruct a scene, we’ll need to re-estimate these parameters; we re-estimate the structure from the motion of cameras… And for this, we’ll rely on feature matching.

What does feature matching have to do with retrieving the relationships of the cameras?
Here is a process to understand:
- From a pair of stereo images…

- We’ll detect features (corners, edges, …) and match them.

- From these, we’ll use heavy mathematics (singular value decomposition, RANSAC (Random sample consensus), and 8-Point Algorithm) to retrieve the motion of cameras through time and their positions.
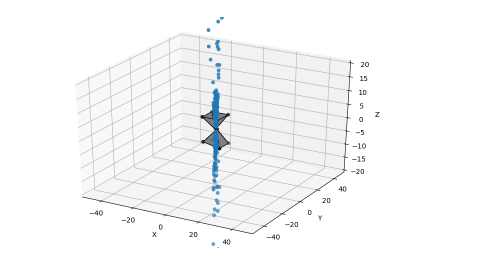
- And finally, recover the structure (3D points) from the motion previously estimated. Hence, the name structure from motion.
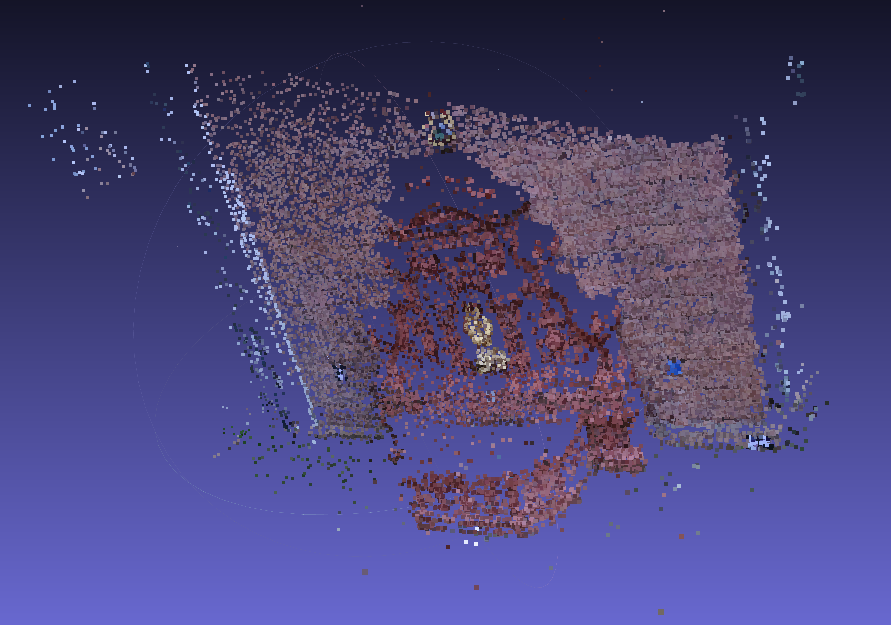
And so this is our Technique #2. Using it, we can work with any pair of digital images, whether we know the parameters or not… and as you guessed, we can also work with multiple consecutive images. But not just consecutives, because what I showed you here is what we could call an “incremental” structure from motion.
There is a family of Structure from Motion algorithms named “Global SfM” where the images don’t even need to belong to the same cameras or same period; it’s just random images of the same scene…
Want to understand it better? Let’s look at an example.
Example: COLMAP
COLMAP is a photogrammetry software doing Multi-View Stereo or Structure from Motion. It’s widely used in the industry to create a dense point cloud from images. I created a little bonus video to show you how it’s easy to reconstruct 3D models from 2D images.
See what we’re doing? First, we capture images, and we may or may not specify the camera location, parameters, lens distortion, or any other parameter. In this example, we’re feeding a file with everything noted.
This, and in particular Structure from Motion, is the king of 3D Reconstruction. It exists as sparse or dense, as incremental or global, and can benefit from advanced techniques such as Bundle Adjustment. Companies have used Photogrammetry to create extremely good-looking 3D models…
So, how good is Photogrammetry?
It’s actually pretty good, especially because we benefit from defined structures, we use geometry, and thus, we can do a lot of reconstruction…
But since 2020, a NeRFs “fever” has taken place online. Have you felt it? Neural Radiance Fields have been about turning an image into a 3D model… but using Deep Learning!
And in an upcoming post, we’ll dive into the 5 main steps to build neural radiance fields!
For now, let’s do a summary of what we learned in this blog.
What's next? We recommend PyImageSearch University.
84 total classes • 114+ hours of on-demand code walkthrough videos • Last updated: February 2024
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary and Next Steps
- There are 3 “main” ways to do reconstruction: Photogrammetry, NeRFs, and Gaussian Splatting. The most popular, used, and acknowledged is Photogrammetry, the science of reconstructing 3D objects from consecutive pairs of 2D images. It consists of two key techniques: Multi-View Stereo and Structure from Motion.
- Multi-View Stereo is the geometric way to reconstruct a scene from multiple pairs of images using depth triangulation and digital camera parameters. The principle relies on iterative 2-View Reconstructions based on Stereo Vision.
- Structure from Motion happens when we don’t know the camera parameters. In this case, we’ll recover them by matching the features of the image and estimating the motion needed from one to another.
- We can code the algorithms ourselves (and it’s much recommended for engineers to learn it), but at an advanced level, we prefer to use libraries such as COLMAP to do the work for us automatically.
Next Steps
If you enjoyed this blog post, I invite you to read my other 3D Computer Vision posts:
- A 5-Step Guide to Build A Pseudo-LiDAR using Stereo Vision: https://www.thinkautonomous.ai/blog/pseudo-lidar-stereo-vision-for-self-driving-cars/
- Computer Vision: From Stereo Vision to 3D Reconstruction: https://www.thinkautonomous.ai/blog/3d-computer-vision/
How to get an Intermediate/Advanced Computer Vision Level?
I have compiled a bundle of Advanced Computer Vision resources for PyImageSearch Engineers who wish to join the intermediate/advanced area. When joining, you’ll get access to the Computer Vision Roadmap I teach to my paid members, and on-demand content on advanced topics like 3D Computer Vision, Video Processing, Intermediate Deep Learning, and more from my paid courses — all free.
Instructions here: https://www.thinkautonomous.ai/py-cv
Citation Information
Cohen, J. “Photogrammetry Explained: From Multi-View Stereo to Structure from Motion,” PyImageSearch, P. Chugh, S. Huot, and R. Raha, eds., 2024, https://pyimg.co/oa19e
@incollection{Cohen_2024_Photogrammetry_Explained,
author = {Jeremy Cohen},
title = {Photogrammetry Explained: From Multi-View Stereo to Structure from Motion},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/oa19e},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.
The post Photogrammetry Explained: From Multi-View Stereo to Structure from Motion appeared first on PyImageSearch.
October 14, 2024 at 06:30PM
Click here for more details...
=============================
The original post is available in PyImageSearch by Jeremy Cohen
this post has been published as it is through automation. Automation script brings all the top bloggers post under a single umbrella.
The purpose of this blog, Follow the top Salesforce bloggers and collect all blogs in a single place through automation.
============================


Post a Comment